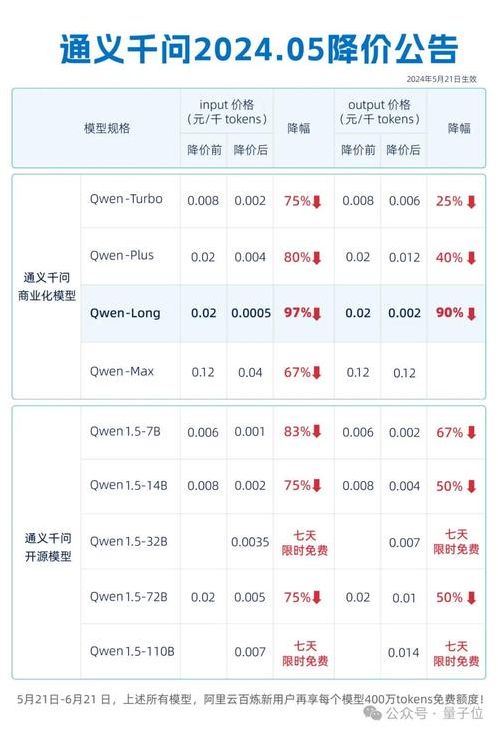
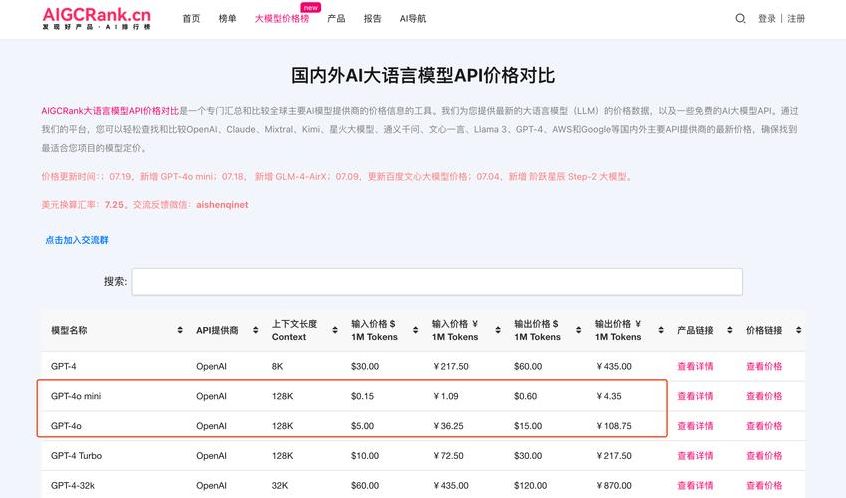
1、DeepSeek-V2的定价为每百万token输入0.14美元(约1元人民币)gpt4token价格,输出0.28美元(约2元人民币gpt4token价格,32K上下文),价格仅为GPT-4-turbo的近百分之一。
2、在科技界,法国初创公司Mistral AI凭借其MoE(Mixture of Experts)模型引发了一场风暴。一款8x7B的小型模型,以惊人的表现击败了Llama 2的70B大模型,被赞誉为初创企业的科技英雄。没有繁冗的发布会,Mistral-MoE的开源特性直接吸引了全球开发者的眼球。
3、首个开源MoE大模型的发布,如同一颗震撼弹,瞬间引爆了AI开发者社区。Mistral AI发布这一模型,标志着MoE架构在开源大模型领域迈出了关键一步。MoE,即专家混合(Mixture-of-Experts)架构,是GPT-4采用的技术方案,也是开源大模型向GPT-4迈进的最接近一集。
4、首个开源MoE大模型由Mistral AI发布,引起AI开发者极大关注。MoE架构全称专家混合,被认为是GPT-4采用的方案,此模型在开源大模型中距离GPT-4最近。Mistral AI以一个磁力链接的形式发布,没有发布会与宣传视频,仅在社区中产生轰动效果。
5、报告还展示了Gemini 5模型在解决真实世界问题的应用案例,如与专业人士合作完成任务,实现时间节省达到26-75%。此外,Gemini 5展示了将英语翻译成Kalamang语言的新能力,达到与人类相似的学习水平。
1、总体而言,阿水AI等此类网站的价值在于其提供了一种接入和使用AI模型的便捷方式,但用户在选择时应充分考虑其背后的技术支持、服务质量和合法性。对于那些追求长期稳定使用的用户,可能需要寻找更加官方和直接的服务渠道。面对不同观点和反馈,用户应保持理性和客观,根据自己的需求和预算做出选择。
2、此外,阿水AI公众号的评论区并不鼓励真实反馈,只展示一些正面评论,这背后反映出他们更倾向于塑造品牌形象,而非提供公正的用户评价。他们选择199元的永久套餐,而非其他订阅选项,显然是为了快速获利,而不考虑长远的用户体验。
3、国内AI绘画网站不断涌现,其中阿水AI(网址:ai.ashuiai.com/drawer)在社交媒体上颇受推崇,吸引了不少使用者。初试体验尚可,让人误以为找到了宝藏,于是购买了高级会员,不料却陷入了陷阱。实际操作中,发现画图功能十分受限,一天产出的画作屈指可数,且质量参差不齐。
4、阿水AI是否值得购买,取决于个人的需求和预算。对于需要高效、智能的语音识别和语音交互功能的用户来说,阿水AI可能是一个不错的选择。然而,对于预算有限或对语音识别技术需求不高的用户来说,阿水AI可能不是必要的购买。阿水AI的优点在于其高效的语音识别和语音交互能力。
5、阿水ai值得买。阿水AI是一个智能聊天机器人,它可以根据用户的输入进行智能回复,并能够模拟人类的聊天行为。如果需要一个能够快速回复消息、提供帮助和解决问题的聊天机器人,并且预算允许,那么阿水AI可能是一个不错的选择。它可以节省时间和精力,帮助您更快地完成工作或解决问题。

6、作为付费用户,我使用阿水AI 0的体验有如下几点:登录网页版时,需要等待约40秒才能进入,估计是因为用户量大,服务器压力较大。偶尔会出现看不懂的英文提示,网络状况不佳时也会遇到连接错误的问题。售后服务水平一般,新功能改进和限制措施并未及时通知到用户,导致体验不佳。
大模型领域内的算力需求巨大,预计训练成本可能突破百亿美元。在算力估算方面,依据《Scaling Laws for Neural Language Models》、《Training Compute-Optimal Large Language Models》等论文,我们进行大致预测。
AI大模型对算力的要求通常较高,这是因为大模型通常具有更多的参数和更复杂的结构,需要更多的计算资源来进行训练和推理。以下是AI大模型对算力的一些常见要求:训练阶段:在训练大模型时,需要进行大量的矩阵运算和梯度计算。
大模型训练所需算力是一个关键议题。训练每参数每 token 的算力需求大致为常数,在训练阶段约为6FLOPs,推理阶段为2 FLOPS。平均算力成本受 GPU 性能影响,每 FLOP 的价格平均约在5年降低40%-50%。
大模型就是一种参数规模非常大的人工神经网络。因为参数足够大之后它能力非常强,所以在很多任务上都表现出非常好的能力。因为大模型学习了非常多的知识,经过了非常多的数据训练,这样就具有了非常好的通用性。包括像我们日常生活中经常见到的各种人工智能产品,比如说人脸识别、对话机器人,等等。
大模型是一种参数规模非常大的人工神经网络。与传统弱人工智能不同,大模型通过扩大参数规模和大量数据训练,能够支持所有人工智能的任务,展现出良好的通用性。 大模型的能力非常强,因为它学习了大量的知识和数据。
1、每个 GPT 模型中的一个 token 占用 4 个字节的空间。这是因为在 GPT 中,tokens 采用的是 32 位浮点数(float32)表示,而每个 float32 类型占用 4 个字节。所以,一个 token 就是占用了 4 个字节的存储空间。
2、第一步:将输入的内容分解成一个个 Token;第二步:结合这些 Token 生成回应。GPT token 的计算包含两部分。输入给 GPT 模型的 token 数和 GPT 模型生成文本的 token 数。
3、大模型中的token是文本数据在被模型处理时被分割成的最小单元。在自然语言处理任务中,大模型如GPT、BERT等需要处理大量的文本数据。为了能够让模型更好地理解和操作这些数据,原始文本会被分割成更小的单元,这些单元就是tokens。它们可以是单词、标点符号、子词等,具体形式取决于模型的词汇表和分词策略。
4、- LLaMA-1:2048个A100 - GPT-5:可能需3万到5万个H100(存疑)GPT-5推理成本计算:参数规模为1750亿,输入500 token长度提示词,输出500 token内容,使用A100实现,算力使用效率为25%,单次推理算力需求为5*10^14 FLOP,成本约为0.003美元/千token。
5、GPT实现中,在预训练部分,使用u表示每一个token,设置窗口长度为k,预测句中的第i个词时,使用第i个词之前的k个词,并根据超参数Θ来预测第i个词最可能的内容。模型由l组隐藏层组成,最初输入隐藏层的数据为词编码U乘词嵌入参数We加上位置参数Wp。
1、以2020年算力水平为例gpt4token价格,使用1片 V100 GPU(在FP16精度下理论算力为28TFLOP)完成此任务,需357年。若要将训练时间缩短至一个月,需要至少购买3000张以上V100(在效率不降gpt4token价格的情况下,实际应更多)。
2、训练算力需求基于单个 token 需要的计算资源 C 约等于 6N,可估算出为达到类似人类的水平,大模型可能需要至少 11 万亿参数、228 万亿 token 数、55*10^28 次的浮点运算。
3、大模型行业快速迭代,客户对训练速度有极高要求,假设训练一个5000亿参数模型,15TB数据,1000P算力需要3年才能完成,而将时间压缩至2周或1个月,则最低需求是10000P算力。
4、在AI技术的快速发展中,万亿参数大模型与超大规模的万卡集群紧密关联。大模型公司如META、微软等已经大量采购英伟达的H100显卡,构建起强大的算力集群,以应对“暴力美学”式的参数和算力需求。国产GPU在这一进程中面临着挑战,但中国工程院院士郑纬民强调gpt4token价格了国产化的必要性。
GPT2模型类似于GPTgpt4token价格,采用单向Transformergpt4token价格,进行了局部调整以提高效率。模型结构图显示了四个版本gpt4token价格,参数量从几千万到15亿不等。GPT2无需fine-tuning流程,直接应用于零样本任务,展现出更大的数据集和模型规模优势。
GPT系列是人工智能技术的重要代表,包括GPT-GPT-GPT-GPT-4等版本。 GPT-1(第一代)gpt4token价格:2018年发布的GPT-1是GPT系列的开山之作,它是一个相对较小的模型。尽管它在生成文本方面已展现出潜力,但在理解和生成高质量回答方面仍有局限。
GPT-1(第一代) gpt4token价格:这是GPT系列的第一个版本, 是一个相对较小的人工智模型, 它是在2018年发布的,已经展示出了一定的生成文本的能力,但在理解复杂问题和生成高质量回答方面仍有限制。
PaLM作为迄今为止训练的最大密集语言模型,参数规模达到540B,需要6144个TPU进行训练,展示了计算资源与基础设施的巨大需求。与GPT-3相比,PaLM在架构、数据集构建、训练方法等方面进行了创新,体现了对模型性能和计算效率的追求。
继续浏览有关 gpt4token价格 的文章